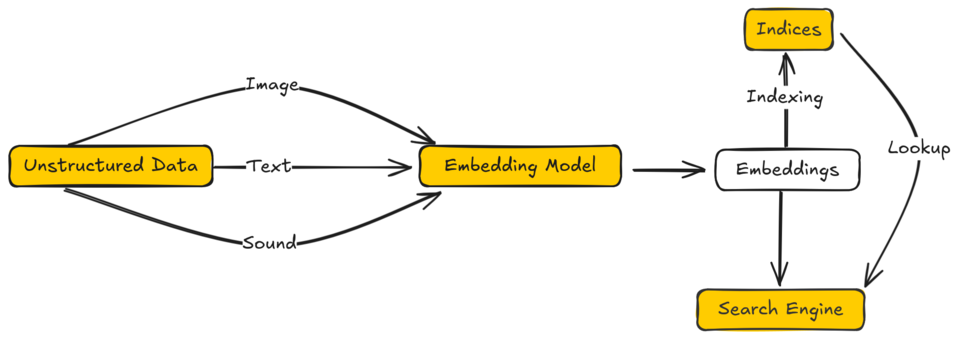
Redis 8.2 ha pasado de ofrecer busqueda vectorial como extension opcional a integrarla como tipo de dato de primer nivel. Esto es mas relevante de lo que parece porque desplaza la pregunta habitual: ya no es si Redis sirve para embeddings, sino si basta para sustituir a un motor dedicado como Qdrant, Weaviate, Milvus o la extension pgvector sobre PostgreSQL. En este post recojo lo que he aprendido montando un par de sistemas RAG este verano con Redis 8.2 en produccion y lo que todavia no compensa pedirle.
Que ha cambiado desde la extension RediSearch
Hasta Redis 7.x la busqueda vectorial vivia dentro del módulo RediSearch, con licencia separada y con la curiosa costumbre de comportarse de forma distinta segun la versión exacta del módulo que tuvieras cargada. En 8.0 la funcionalidad se integro en el nucleo bajo la licencia abierta del propio Redis, y en 8.2 se ha cerrado la API con soporte para índices HNSW, planificacion por metadatos filtrables y métricas de latencia por cola de consulta. El cambio importante es que ya no hay que tratar la capa vectorial como un anadido fragil, sino como parte del motor que tu equipo conoce.
La implementación mantiene la filosofia de Redis. Los vectores son campos dentro de documentos hash o JSON, el índice HNSW se construye en memoria, y la consulta se expresa con el lenguaje de RediSearch que ya se usaba para texto completo. Esto significa que una sola consulta puede combinar filtros booleanos sobre etiquetas con un KNN sobre embeddings sin cruzar de sistema. En la práctica, para un RAG sencillo donde filtras por tenant y buscas los cinco documentos mas cercanos, la consulta cabe en una linea.
Rendimiento medido con cargas pequenias y medianas
Las cifras que publica Redis Labs son optimistas pero no mentirosas. En mis pruebas con un corpus de 800.000 vectores de 768 dimensiones y una maquina con 32 GB de RAM, Redis 8.2 respondia consultas KNN con k igual a 10 en una mediana de 4 a 6 ms, con un percentil 99 por debajo de 20 ms. Para el mismo corpus, pgvector con un índice HNSW sintonizado devolvia entre 15 y 30 ms y Qdrant se movia en un rango similar al de Redis. La diferencia es consistente pero moderada, no de un orden de magnitud.
Donde Redis gana de forma clara es cuando la aplicacion ya depende de Redis para cache, sesiones o colas. Evitar un sistema adicional tiene valor operativo real: menos backups, menos monitoreo, menos permisos, menos tuberias por donde romperse. En equipos pequenios, esta consolidacion compensa incluso si el motor dedicado es un 20% mas rapido en el papel.
Donde el motor dedicado sigue ganando
A partir de varios millones de vectores la historia cambia. El índice HNSW de Redis vive entero en memoria, y aunque la biblioteca base es eficiente, una tabla de 50 millones de vectores a 768 dimensiones pide alrededor de 150 GB de RAM solo para el índice. Qdrant y Milvus soportan índices persistidos a disco con capa de cache caliente, lo que permite servir corpus grandes en maquinas razonables. pgvector en PostgreSQL 17 admite índice HNSW sobre almacenamiento persistente desde 2024, y eso cambia el cálculo económico para corpus grandes aunque con latencias mas altas.
El segundo punto donde un motor dedicado gana es en capacidades avanzadas de filtrado. Redis permite filtros booleanos sobre etiquetas y rangos numericos, pero Qdrant y Weaviate ofrecen filtros geoespaciales, payloads ricos y estrategias de preseleccion adaptativa que importan cuando la cardinalidad del filtro es alta. En un caso real de busqueda multilingue con 200 tenants, vi como Qdrant mantenia latencias estables donde Redis empezaba a degradarse porque el planificador tenia menos información sobre la selectividad.
La pieza que suele olvidarse: ingesta
Hablar de busqueda es solo la mitad del trabajo. La otra mitad es meter los vectores y mantenerlos actualizados. Redis tiene a su favor la escritura en memoria con latencias muy bajas, lo que hace que la construccion del índice HNSW sea rapida mientras el corpus cabe en RAM. En mis pruebas insertar 100.000 vectores de 1024 dimensiones tardo 18 segundos, consumiendo un hilo a plena carga. Para corpus pequenios que se reconstruyen diariamente, esto basta.
La pega es que HNSW no soporta bien eliminaciones masivas. Borrar 10% del corpus deja el grafo fragmentado y degrada la calidad del recall. Redis no expone todavia una operación de reconstruccion incremental, asi que el patron que he acabado usando es reconstruir el índice completo cada noche si la tasa de borrado pasa del 5% semanal. Motores dedicados como Qdrant ofrecen compactacion asincrona que evita esta gimnasia, y para flujos de documentos con mucha rotacion esto marca la diferencia.
Coherencia con el resto de Redis
El detalle que hace que Redis 8.2 sea interesante para muchos casos no es tanto el rendimiento como la coherencia operativa con el resto del sistema. Si el equipo ya gestiona replicacion, backups con RDB y AOF, conmutacion con Sentinel o cluster, y politicas de expulsion, esa experiencia aplica directamente a los índices vectoriales. No hay un sistema nuevo que aprender ni un modelo de consistencia distinto que contar al equipo de guardia.
Este valor sube a medida que el equipo es pequenio. En una organizacion con dos personas operando infraestructura, anadir Qdrant o Weaviate significa un binario nuevo, un protocolo de gestión nuevo, un patron de backup nuevo y alertas nuevas. Redis 8.2 reutiliza el 80% de lo que ya funciona. Para un equipo de quince personas con SRE dedicado, esta ventaja se diluye.
Como decidir en 2025
Mi regla práctica tras estos meses es sencilla. Si el corpus vectorial cabe en RAM de una maquina razonable, si la aplicacion ya usa Redis, y si los filtros son básicos, Redis 8.2 es la eleccion por defecto. El ahorro operativo compensa cualquier ventaja puntual de un motor dedicado. Si el corpus supera los 10 millones de vectores, si los filtros son complejos, o si hay requisitos de retencion muy grandes con acceso poco frecuente, un motor dedicado ofrece mejor relacion entre coste y rendimiento.
Hay una zona intermedia, entre 1 y 10 millones de vectores, donde la decision depende mucho del patron de consulta. Si las consultas son muy concurrentes y sensibles a latencia, Redis gana. Si son esporadicas pero sobre corpus grandes y rotativos, Qdrant o pgvector ganan. En esa zona conviene medir con el propio corpus antes de comprometerse.
Mi lectura
Redis 8.2 cierra una brecha que Redis llevaba arrastrando desde 2022. El hueco no era técnico sino de posicionamiento: se percibia como cache rapida al lado de una base de datos seria, y la busqueda vectorial confirmaba esa imagen. Con el índice como tipo nativo y la licencia abierta, Redis pasa a competir en serio con pgvector en la franja media de corpus, y eso es un cambio de categoría para la plataforma.
No creo que Redis sustituya a los motores dedicados en el segmento alto. Qdrant, Milvus y Weaviate siguen siendo mejores cuando hay que servir cientos de millones de vectores con filtros complejos. Pero para la gran mayoria de aplicaciones RAG que veo en empresas medianas, donde el corpus es de unos pocos millones y la complejidad de filtrado es baja, Redis 8.2 es una opcion sobria y suficiente.
Lo que mas me gusta del cambio es que simplifica la arquitectura. Cada sistema extra en produccion tiene coste oculto en personal, monitoreo y seguridad. Si tu caso encaja, usar Redis tanto para cache como para embeddings es una de esas decisiones que reducen complejidad sin perder capacidad. Y eso, en 2025 con los equipos de infraestructura tan tensionados, vale mucho mas que un 20% de latencia.